Scoring Metrics
Leaderboards
Antigranular is not just a platform. It's a competition, a race to be at the forefront of privacy-first data science. And what better way to track this race than with our dynamic leaderboards?
Just like you'd find on Kaggle or DrivenData, our leaderboards rank participants based on their performance in the competition. But here's the Antigranular twist: we also take into account the privacy budget.
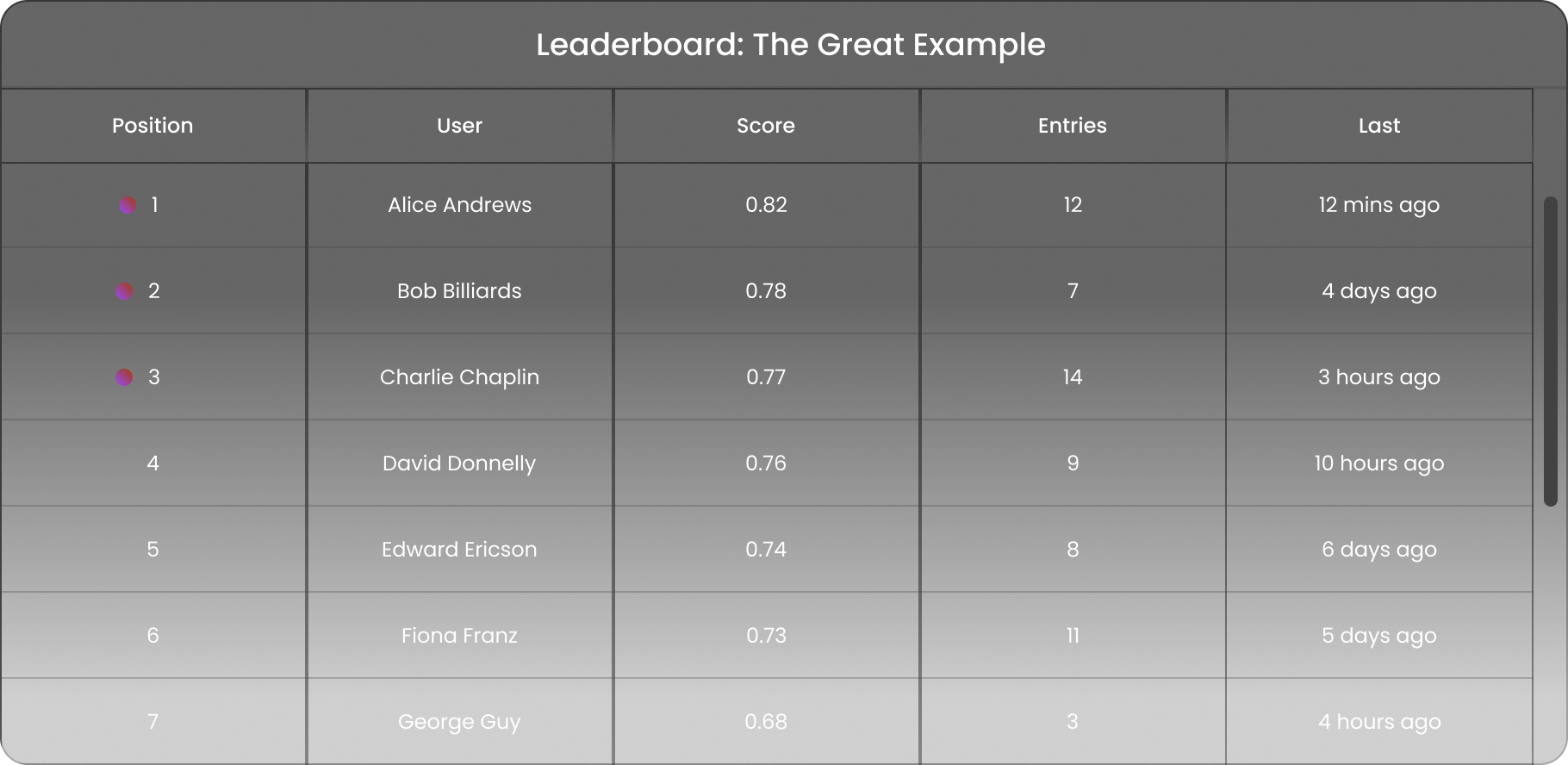
Overview
As like any other competition, strategic submissions are key to success. We encourage you to focus on building robust models that generalize and can be broadly applied to the problem, not just the test dataset. While the live leaderboard offers valuable feedback, it is the hidden validation subset that determines your final score, so we encourage participants to prioritize quality over quantity in your solutions. We detail additional information about both of these subsets in the next section.
How are submissions evaluated?
When you submit a modelling prediction, your submission is divided into two subsets:
Live Leaderboard Subset: The live leaderboard reflects results based on one subset of your submission. This live feedback allows you to track your performance in real-time, adding an extra layer of excitement and challenge. The result shown on the score column will be determined both by the accuracy of your solution and your epsilon usage. For details about the specifics scoring metrics used, please visit this page.
Validation Subset: The remaining subset is reserved for final scoring. This subset remains hidden throughout the competition to minimize overfitting and ensure fairness. It is used at the end of the competition to determine the final rankings. Your final score is completely determined by the validation subset. Although a high score on the live leaderboard could imply a successful approach, the validation subset allows us to fairly judge entries, which are detailed in the next section.
What does the entries column track?
The leaderboard includes a count of entries for each participant, providing transparency into the number of submissions made. Participants who make more than 20 submissions are marked with a red asterisk to highlight high activity. This feature encourages thoughtful submissions and discourages strategies that aim to perfectly fit to the live leaderboard subset.
Please note that in the attempt to optimise for your leaderboard score you may accidentally overfit your model to it, losing useful feedback on the actual performance of your model. Furthermore, attempting to brute-force a high score on the test subset will negatively impact your final results due to producing an overfitted prediction vector. In practice, these excessive submissions may appear to lead to solutions that perform perfectly on the live leaderboard, but since they may not generalize properly, they are likely to yield poor results on the hidden validation dataset. Both overfitting and brute-forcing are approaches that should not be considered in the participant's interest, as they often lead to a lower ranking than expected when calculating the final score.
Overall, we encourage participants to keep in mind that although strong performance on the live leaderboard is a potentially good indicator of the quality of their underlying strategy, it does not necessarily translate into success in the final rankings. Finally, as you review the leaderboard ahead of your participation, do not be discouraged and remember that the same thought process applies: leading participants with exceptionally high scores and a significant number of entries may experience shifts in their rankings once validation scores are factored in.