Platform
Connecting to a Dataset
You can connect to a dataset in a similar way to a competition:
Start by signing up or signing in to Antigranular. You can do so with a username and password or with your Google or GitHub OAuth.
Navigate to the dataset you are interested in. You will be able to access detailed information about the dataset, including metadata, the licence, and more.
On the same page, you will see a code snippet in the top right corner like this:
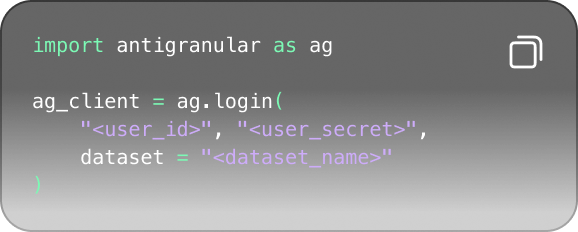
Click on the code snippet to copy it. The code will contain your OAuth client ID and secret for the dataset. Paste the code into your Jupyter Notebook and run the cell.
About our Datasets
In the realm of data science and machine learning, gaining hands-on experience is crucial for honing skills and mastering new frameworks. Antigranular provides a curated collection of open source datasets aimed at enabling users to get their hands dirty, experiment, and become familiar with the tools and techniques of the framework.
While these datasets are readily available online, Antigranular's primary objective is to offer users familiar and accessible data that encourages exploration and experimentation beyond traditional competition scenarios. By leveraging these datasets, users can delve into real-world problems, test algorithms, and gain practical insights while developing a strong foundation in data science.
- Dataset Diversity:
We strive to offer a diverse and expanding range of datasets covering various domains, including but not limited to finance, healthcare, social sciences, and natural language processing. New datasets will be regularly added and if you have any recommendations for datasets you'd like to work with, please let us know on Discord.
- Realistic and Quality Data:
The datasets aim to provide a level of realism. The data is sourced from reputable and reliable sources, ensuring accuracy and relevance. By working with real-world datasets, users can gain exposure to the complexities and nuances of data processing, cleaning, and feature engineering, which are crucial steps in any data science workflow.